
How Biblibuddy Works
Built for academics who value their time and their reputation
Biblibuddy performs three core functions:
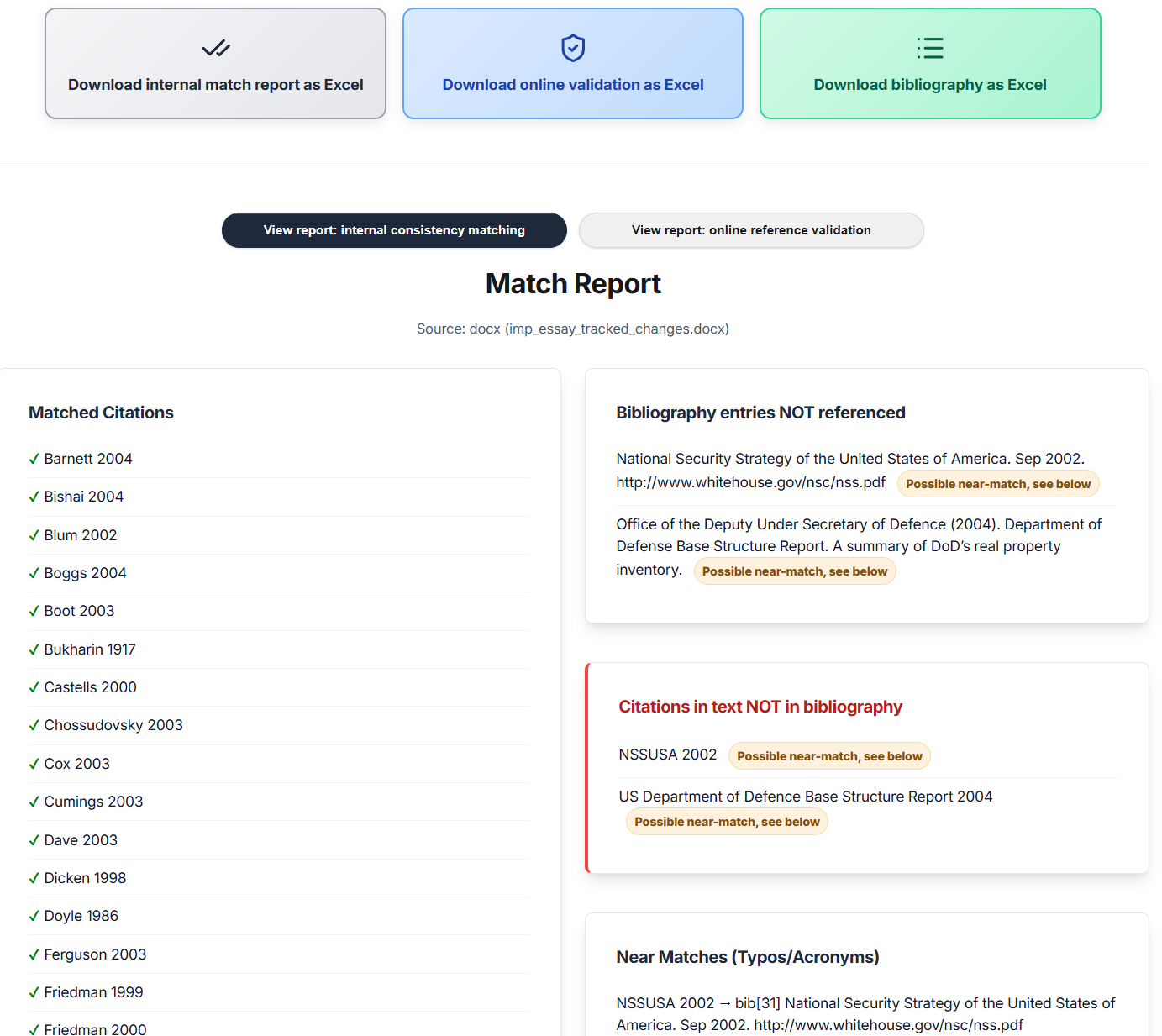
- Internal consistency checking (Harvard citation style only, this simply isn't a problem to be solved with footnote/endnote styles because the links are already created automatically): It helps you ensure that all and only your in-text references are in your bibliography and vice versa. It identifies missing or extra references and catches near-misses (e.g. typos, year or edition discrepancies, accents, year suffix errors etc), and flags ambiguous citations that could refer to multiple bibliography entries.
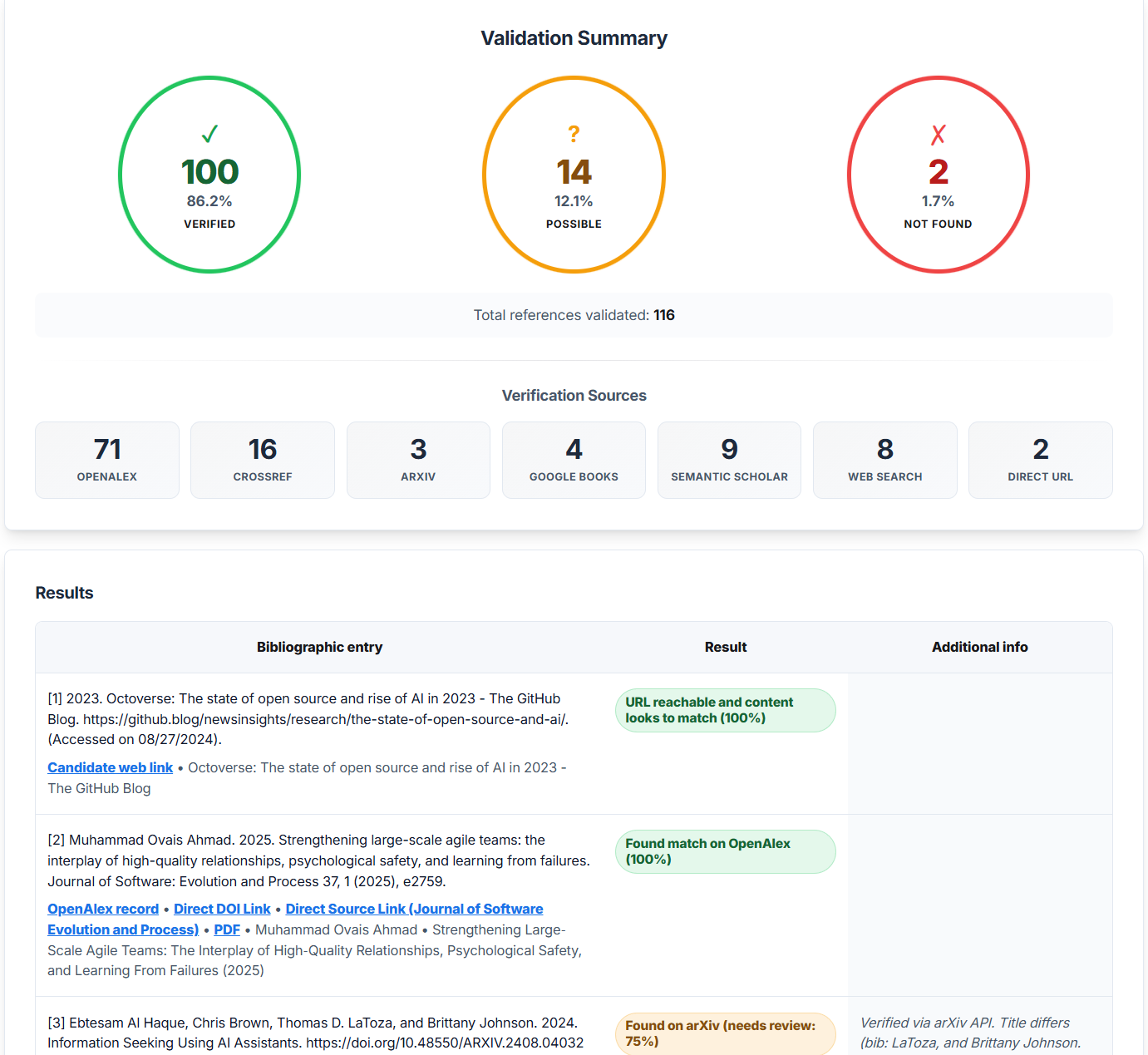
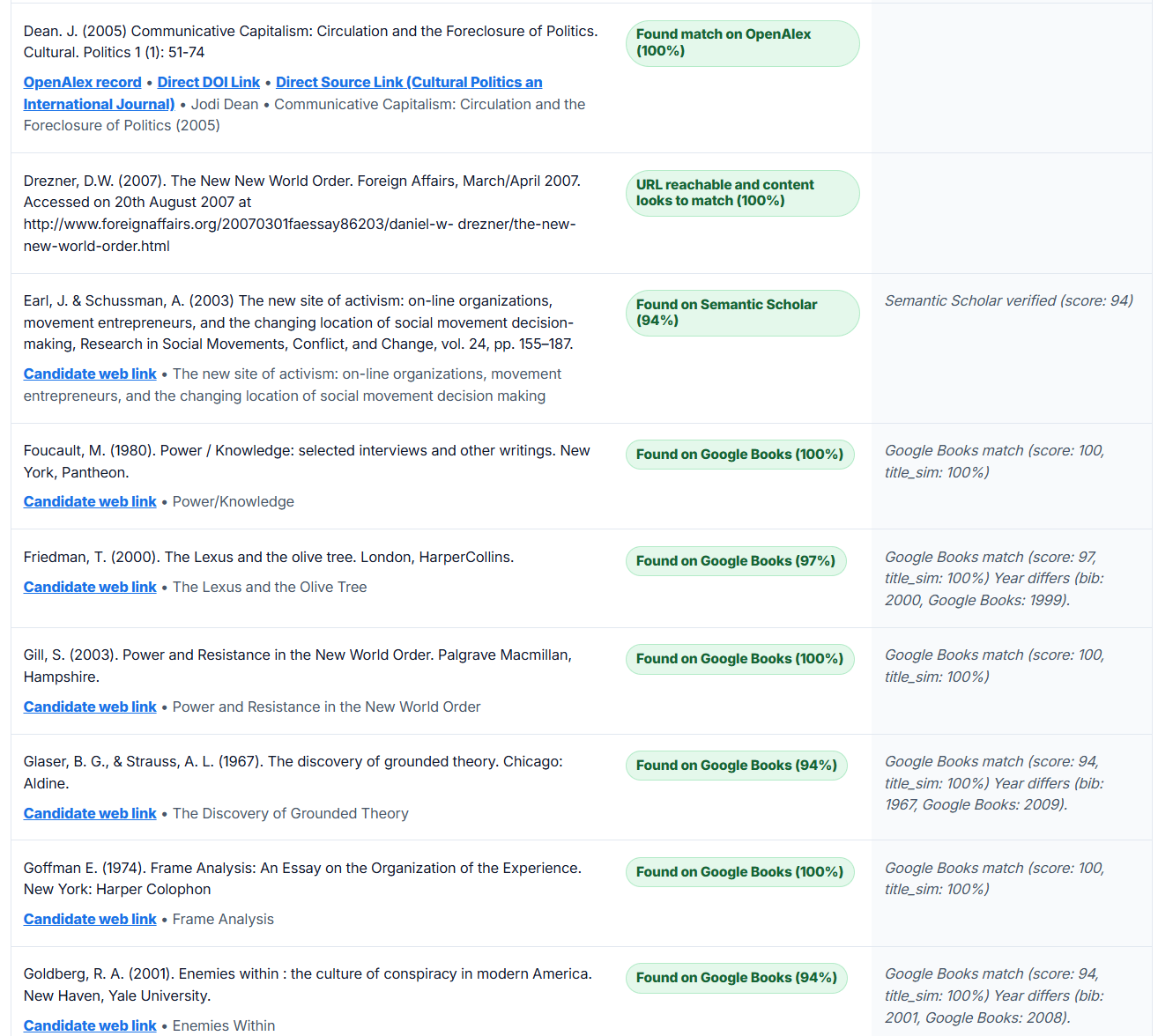
- Online reference verification: Validates your bibliography entries against authoritative scholarly databases and web sources, flagging entries that can't be verified and providing you with evidence links for those that can.
- Structured bibliography export: Exports your bibliography to Excel in a structured format, making it easier to clean up, reuse, or integrate into other workflows like developing a structured reading list.
Biblibuddy produces clean, intuitive and detailed reports in a couple of minutes that highlight issues and provide actionable evidence. It does NOT edit your document for you.
Example report screenshots
Internal consistency report
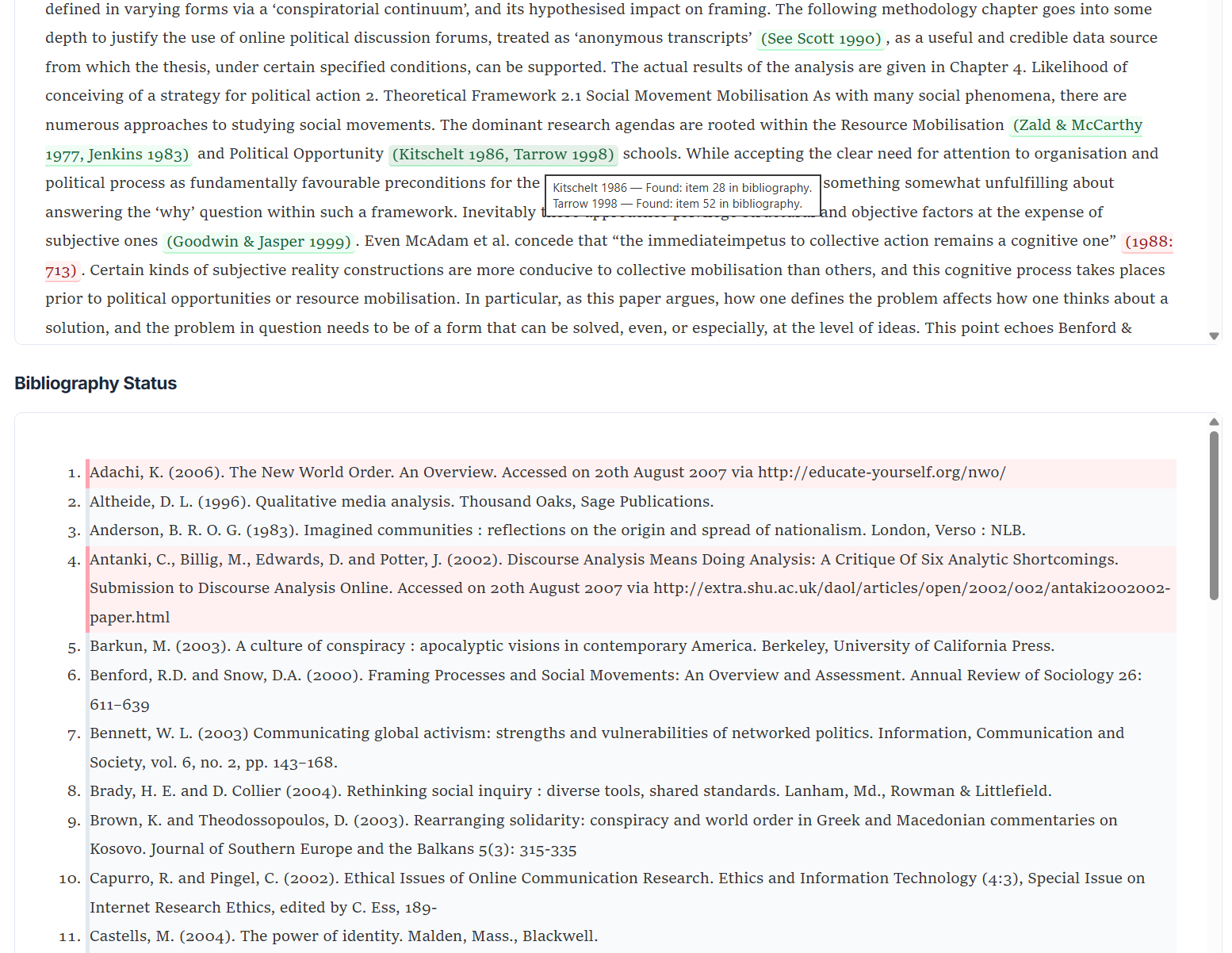
Online validation report
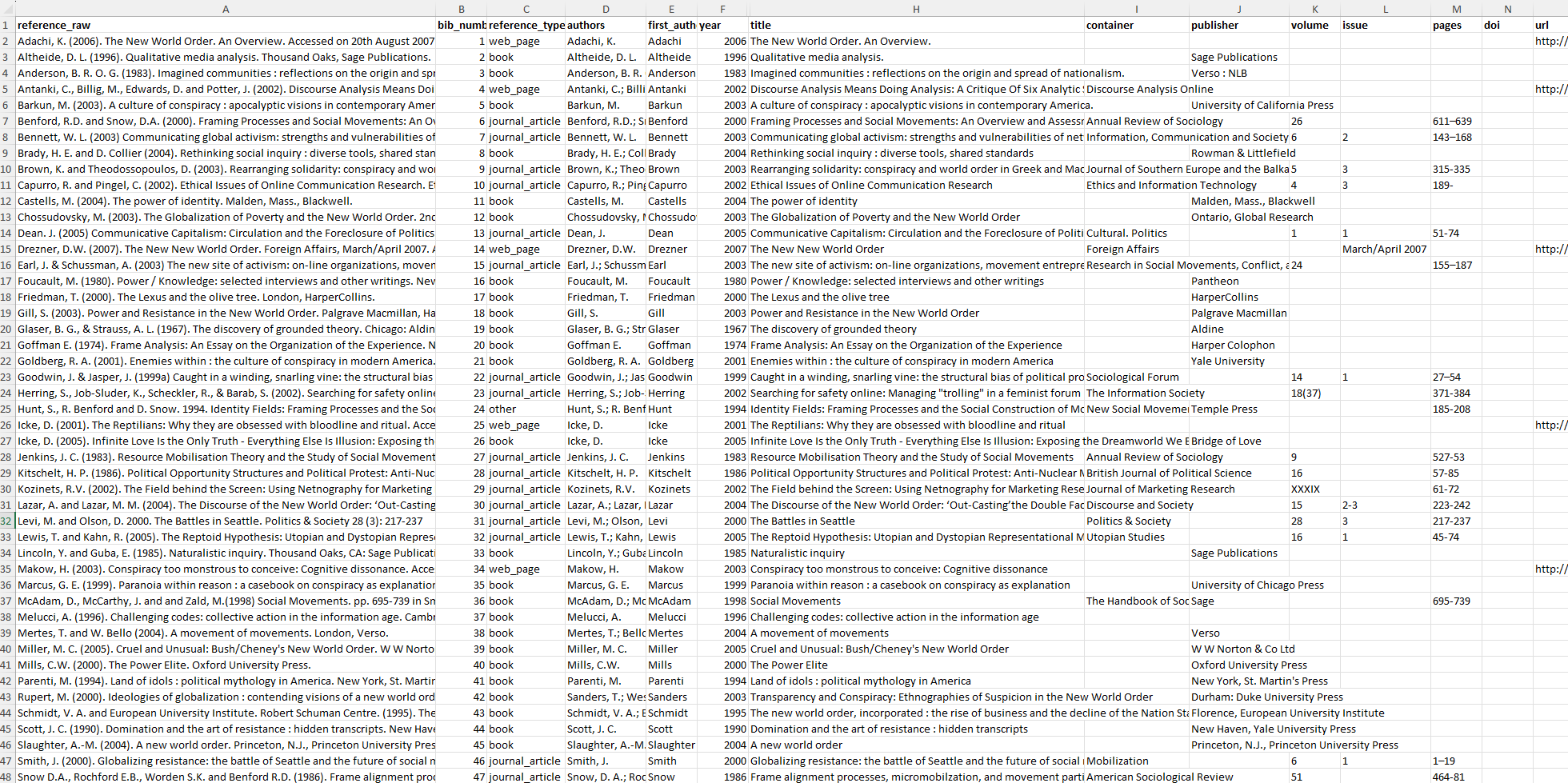
Structured bibliography export to Excel
Minimal AI, Maximum Rigour: How Biblibuddy Actually Works
Many academics assume that AI chatbots should be able to handle referencing checks in a single prompt, because it's "easy" and something an intern could do. But that assumption fundamentally misunderstands both how large language models work and the complexity of rigorous reference validation. This is not a single task. It's hundreds of micro-tasks, each of which has to be checked off systematically. No AI chatbot can do this reliably, as anybody who has tried knows. Asking a chatbot to one-shot this is like asking an intern to read your paper start to finish without taking notes and then from memory give you a list of which references matched or didn't and which ones might have typos. Same goes for online validation, that's a huge number of tasks each of which has to be logged. To do this rigorously the intern would have to note down each individual step and log results for a final accurate review. That's exactly what Biblibuddy does, each AI task is a micro-task as part of a controlled, orchestrated workflow.
The Scholarly APIs used
Biblibuddy take a multi-pronged approach to validate your references by querying several authoritative scholarly databases and catalogues, with web search as a fallback or when a bibliography entry was classified by the AI as non-scholarly (e.g. govt / consultancy report, media article etc.):
- OpenAlex: A comprehensive scholarly index covering millions of works across disciplines.
- CrossRef: The authoritative DOI registration agency, used to verify DOI-based references quickly and reliably.
- Semantic Scholar: Research tool from the Allen Institute, used as a backup when OpenAlex is uncertain.
- arXiv: The preprint repository for physics, mathematics, computer science, and related fields.
- Google Books: Used to verify book references and ISBNs.
- Web search: Used as a fallback for hard-to-verify references, such as grey literature, reports, or references with year mismatches in scholarly databases. If a bibliography entry includes a URL, the app checks that first including comparing the content to ensure it's actually what the right link
Where AI is actually used (and why)
AI in Biblibuddy is not generative guesswork. It's used for specific, targeted tasks where interpretive intelligence is necessary:
- Extracting structured information from bibliography entries: Parsing author names, years, titles, venues, DOIs, and ISBNs from the semi-structured text of bibliography entries.
- Identifying in-text citations: Detecting narrative and parenthetical citations in the body text, including edge cases like "ibid", dual-author forms, year-only references with nearby context, separate indented quoters, and complex sentences which separate author and year/page refs. This is where things get really messy and an AI is needed.
- Classifying references as scholarly or non-scholarly: Determining whether a reference should be validated via scholarly APIs or web search to avoid wasted searches (no point trying Semantic Scholar for a BBC article!).
- Reviewing near-misses: Identifying potential typos or abbreviations in citations that might explain mismatches (e.g., "Smith" vs "Smith-Jones", "2020" vs "2021" - these slip-ups need AI).
- Selecting the best candidate from search results: When multiple potential matches are returned by an API, the AI helps identify which result best corresponds to the bibliography entry.
Privacy-first by design even though it makes things less convenient
I know my audience. I've worked in academia for over 20 years. Concerns are high right now especially when it comes to AI accessing academic content. Biblibuddy is built on a simple principle: your content is never saved.
- No full-text storage: Biblibuddy never saves your document text, bibliography, or report data to disk or any database. All processing happens in memory, and when the session ends, your content is gone. This app is being run on a shoestring and doc storage is expensive anyway!
- No AI sees your full paper: AI models only receive small, targeted chunks, e.g. individual bibliography entries or citation spans, for specific interpretive tasks. This app is fundamentally all about the referencing metadata to help with the drudge work, the content itself is irrelevant.
- What does get saved: The only data persisted is limited operational metadata for billing, account security, debugging and service operation: your email, login timestamps, run counts, API token usage and bibliographic entries (for caching benefits).
- Trade-offs for privacy: This privacy-first design means that if your connection drops mid-run, the work will be lost. There's no "resume from where you left off" because nothing is saved. This will be painful for you if that scenario ever happens, but the privacy benefit is worth it.
The Human-in-the-Loop Philosophy
I'm an emphatic human-in-the-loop fundamentalist when it comes to AI. The idea of letting an AI automatically edit a live draft document behind the scenes is insane to me. Even if you plead for it, I won't add any such feature.
Biblibuddy quickly produces a report which you use to fix issues yourself, maintaining full editorial control.
This approach respects the reality that you are the expert on your work. Biblibuddy provides evidence and flags potential issues that will have emerged from careless slip-ups rather than academic judgement. The report is structured to make corrections as easy as possible, with clear issue descriptions, evidence links, and actionable recommendations. But the final decisions i.e. what to fix, what to ignore, what to investigate further etc. are always yours.
Structured Export to Excel: Reuse Your Bibliography Data
A high value feature of Biblibuddy is the ability to export your bibliography to Excel in a structured format.
The export includes parsed fields for each bibliography entry:
- Authors
- Year (with suffix, if applicable)
- Title
- Container (journal, book title, etc.)
- Publisher, volume, issue, pages
- DOI and URL
- Reference type (journal article, book, chapter, etc.)
This structured export is useful for:
- Cleaning up and standardising bibliography entries across multiple drafts.
- Reusing references in future papers or grant applications.
- Departmental or institutional workflows e.g. generating reading lists.
- Importing into reference management tools or databases for analytics.
Designed to be conservative and cautious
Biblibuddy is intentionally conservative. When in doubt, it flags items as possible rather than verified. Sometimes web search results simply don't have all the info to identify a perfect match (e.g. the publication year) - this app never accesses scholarly content from publishers, it simply searches and evaluates citation databases and web search results for the referencing metadata to identify the best match.
This means:
- Some perfectly valid references may be flagged as "possible" if the validation evidence is ambiguous (e.g., a book review in OpenAlex instead of the book itself, or a large year mismatch) even if to your eyes it looks like a slam dunk match.
- Author-aware validation prevents false positives. Biblibuddy won't mark a reference as verified if the title matches but the author doesn't. This might be annoying in cases where an author was added to a future version, but it's always better to err on the side of caution.
- Near-miss suggestions are surfaced explicitly for you, rather than silently auto-corrected.